
Analizando las PASO
Hace unos días tuvimos elecciones en Argentina. Unas multitudinarias primarias que no eligen nada pero a la vez eligieron todo. La importancia del evento, y el hecho de que los datos de cada mesa de votación son publicados en la web (ver aquí), me hizo pensar que era una idea interesante mostrar como leer estos datos en R y hacer algunos cálculos y visualizaciones simples. La idea es que, partiendo de estos archivos de texto, vamos a generar mapas con el porcentaje de voto que sacó cada partido. ¡Arranquemos!
Cuando descarguen y descompriman los datos van a ver los siguientes archivos:
- descripcion_postulaciones.dsv
- mesas_totales.dsv
- descripcion_regiones.dsv
- mesas_totales_agrp_politica.dsv
- mesas_totales_lista.dsv
Preparación de las tablas
En este post vamos a usar dos de ellos: mesas_totales y descripcion_postulaciones. Los pueden abrir con el bloc de notas y van a ver que son archivos de texto separados por barras verticales. ¿Cómo los leemos en R?
## Cargamos los paquetes necesarios
library("raster")
library("leaflet")
library("tidyverse")
## Seteamos el directorio de trabajo
setwd("/home/datos/paso2019/120819-054029/")
## Cargamos datos de las mesas
mesas_lista <- read_delim("mesas_totales_lista.dsv", delim="|")
mesas_lista
# A tibble: 3,665,201 x 8
CODIGO_DISTRITO CODIGO_SECCION CODIGO_CIRCUITO CODIGO_MESA CODIGO_CATEGORIA
<chr> <chr> <chr> <chr> <chr>
1 01 01001 01001000001 0100100001X 000100000000000
2 01 01001 01001000001 0100100001X 000100000000000
3 01 01001 01001000001 0100100001X 000100000000000
4 01 01001 01001000001 0100100001X 000100000000000
5 01 01001 01001000001 0100100001X 000100000000000
6 01 01001 01001000001 0100100001X 000100000000000
7 01 01001 01001000001 0100100001X 000100000000000
8 01 01001 01001000001 0100100001X 000100000000000
9 01 01001 01001000001 0100100001X 000100000000000
10 01 01001 01001000001 0100100001X 000100000000000
# … with 3,665,191 more rows, and 3 more variables: CODIGO_AGRUPACION <chr>,
# CODIGO_LISTA <chr>, VOTOS_LISTA <dbl>
En las PASO los porcentajes se calculan sobre el total de votos válidos (incluye voto en blanco) mientras que en las generales se calcula sobre el total de votos válidos positivos (no los incluye). Por lo tanto necesitamos obtener el número de votos en blanco, que no está en la tavla mesas_totales_agrp_politica sino en mesas_totales:
## Voto por categoria (blanco, impugnado, etc)
vcat <- read_delim("mesas_totales.dsv", delim="|")
vcat
# A tibble: 1,719,994 x 7
CODIGO_DISTRITO CODIGO_SECCION CODIGO_CIRCUITO CODIGO_MESA CODIGO_CATEGORIA
<chr> <chr> <chr> <chr> <chr>
1 01 01001 01001000001 0100100001X 000100000000000
2 01 01001 01001000001 0100100001X 000100000000000
3 01 01001 01001000001 0100100001X 000100000000000
4 01 01001 01001000001 0100100001X 000100000000000
5 01 01001 01001000001 0100100001X 000201000000000
6 01 01001 01001000001 0100100001X 000201000000000
7 01 01001 01001000001 0100100001X 000201000000000
8 01 01001 01001000001 0100100001X 000201000000000
9 01 01001 01001000001 0100100001X 000301000000000
10 01 01001 01001000001 0100100001X 000301000000000
# … with 1,719,984 more rows, and 2 more variables: CONTADOR <chr>, VALOR <dbl>
Como se puede ver los datos de la mesa y de los partidos políticos están codificados. Para saber a que corresponden necesitamos la información que está en el archivo descripcion_postulaciones:
## Codigos provincias
desc_prov <- data.frame(CODIGO_DISTRITO = c("02", "04", "21", "01", "13",
"23", "08", "17", "14", "05", "22", "06", "18", "16", "15", "10",
"09", "07", "19", "11", "12", "03", "20", "24"),
PROV = c("Buenos Aires", "Córdoba", "Santa Fe", "Ciudad de Buenos Aires","Mendoza",
"Tucumán", "Entre Ríos", "Salta", "Misiones", "Corrientes", "Santiago del Estero",
"Chaco", "San Juan", "Río Negro", "Neuquén", "Jujuy", "Formosa","Chubut",
"San Luis", "La Pampa", "La Rioja", "Catamarca", "Santa Cruz",
"Tierra del Fuego"))
## Descripcion postulaciones
desc_post <- read_delim("descripcion_postulaciones.dsv", delim="|")
desc_post
# A tibble: 1,442 x 6
CODIGO_CATEGORIA NOMBRE_CATEGORIA CODIGO_AGRUPACI… NOMBRE_AGRUPACI…
<chr> <chr> <chr> <chr>
1 000801000000000 Diputados Ciuda… 01-504 CONSENSO FEDERAL
2 000801000000000 Diputados Ciuda… 13 MOVIMIENTO AL S…
3 000801000000000 Diputados Ciuda… 5 DEMOCRATA CRIST…
4 000801000000000 Diputados Ciuda… 87 UNITE POR LA LI…
5 000801000000000 Diputados Ciuda… 87 UNITE POR LA LI…
6 000801000000000 Diputados Ciuda… 01-502 FRENTE DE TODOS
7 000801000000000 Diputados Ciuda… 88 PARTIDO DIGNIDA…
8 000801000000000 Diputados Ciuda… 01-187 AUTODETERMINACI…
9 000801000000000 Diputados Ciuda… 01-501 FRENTE DE IZQUI…
10 000801000000000 Diputados Ciuda… 01-503 JUNTOS POR EL C…
# … with 1,432 more rows, and 2 more variables: CODIGO_LISTA <chr>,
# NOMBRE_LISTA <chr>
Ahora podemos relacionar las dos tablas mediante los códigos y reemplazarlos por el nombre que corresponde:
agrup <- desc_post %>%
select(CODIGO_AGRUPACION, NOMBRE_AGRUPACION) %>%
distinct()
mesas <- left_join(mesas_lista, agrup, by="CODIGO_AGRUPACION") %>%
select(-CODIGO_AGRUPACION, -CODIGO_LISTA)
El siguiente paso es agregar los votos en blanco:
vblanco <- vcat %>%
filter(CONTADOR == "VB") %>%
rename("VOTOS_LISTA" = VALOR) %>%
mutate(NOMBRE_AGRUPACION = "EN BLANCO") %>%
select(-CONTADOR)
mesas <- bind_rows(mesas, vblanco) %>% arrange(CODIGO_MESA)
Agregamos la descripción de la categoría (presidente, diputados, etc):
categoria <- desc_post %>%
select(CODIGO_CATEGORIA, NOMBRE_CATEGORIA) %>%
distinct()
mesas <- left_join(mesas, categoria, by="CODIGO_CATEGORIA") %>%
select(CODIGO_DISTRITO, NOMBRE_AGRUPACION, NOMBRE_CATEGORIA, VOTOS_LISTA)
Y el nombre de la provincia:
mesas <- left_join(mesas, desc_prov, by="CODIGO_DISTRITO") %>%
select(PROV,NOMBRE_CATEGORIA, NOMBRE_AGRUPACION, VOTOS_LISTA)
El último paso de esta etapa es filtrar la tabla. Esta tabla contiene los resultados de todas las elecciones que ocurrieron el domingo, incluyendo elecciones provinciales y municipales. En este momento solo nos interesan las presidenciales:
mesas <- mesas %>% filter(NOMBRE_CATEGORIA == "Presidente y Vicepresidente de la República")
Cálculo de totales y porcentajes por provincia
A la tabla con los votos por mesa la voy a condensar para obtener los resultados a nivel de provincia:
xprov <- mesas %>% select(PROV, NOMBRE_AGRUPACION, VOTOS_LISTA) %>%
group_by(PROV, NOMBRE_AGRUPACION) %>%
summarize(VOTOS=sum(VOTOS_LISTA)) %>%
arrange(PROV, desc(VOTOS))
xprov
# A tibble: 264 x 3
# Groups: PROV [24]
PROV NOMBRE_AGRUPACION VOTOS
<fct> <chr> <dbl>
1 Buenos Aires FRENTE DE TODOS 4661554
2 Buenos Aires JUNTOS POR EL CAMBIO 2749946
3 Buenos Aires CONSENSO FEDERAL 711181
4 Buenos Aires FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD 319253
5 Buenos Aires EN BLANCO 304904
6 Buenos Aires UNITE POR LA LIBERTAD Y LA DIGNIDAD 174887
7 Buenos Aires FRENTE NOS 171376
8 Buenos Aires MOVIMIENTO AL SOCIALISMO 71935
9 Buenos Aires FRENTE PATRIOTA 22581
10 Buenos Aires PARTIDO AUTONOMISTA 8783
# … with 254 more rows
Y voy a calcular los porcentajes que obtuvo cada partido en cada provincia:
xprov %<>%
group_by(PROV) %>%
mutate(PCT=round(VOTOS / sum(VOTOS) * 100,2)) %>%
ungroup()
xprov
# A tibble: 264 x 4
PROV NOMBRE_AGRUPACION VOTOS PCT
<fct> <chr> <dbl> <dbl>
1 Buenos Aires FRENTE DE TODOS 4661554 50.7
2 Buenos Aires JUNTOS POR EL CAMBIO 2749946 29.9
3 Buenos Aires CONSENSO FEDERAL 711181 7.73
4 Buenos Aires FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD 319253 3.47
5 Buenos Aires EN BLANCO 304904 3.31
6 Buenos Aires UNITE POR LA LIBERTAD Y LA DIGNIDAD 174887 1.9
7 Buenos Aires FRENTE NOS 171376 1.86
8 Buenos Aires MOVIMIENTO AL SOCIALISMO 71935 0.78
9 Buenos Aires FRENTE PATRIOTA 22581 0.25
10 Buenos Aires PARTIDO AUTONOMISTA 8783 0.1
# … with 254 more rows
Creación de los mapas
Vamos a llevar los datos a un formato que nos sirva para crear los mapas. Lo que voy a hacer es crear una tabla que en las filas tiene las provincias (24) y en las columnas los partidos políticos (11). Dentro de la tabla estarán los porcentajes que obtuvo cada partido político en cada provincia:
xprov_wide <- xprov %>%
select(-VOTOS) %>%
spread(NOMBRE_AGRUPACION, PCT)
xprov_wide
# A tibble: 264 x 3
# Groups: PROV [24]
PROV NOMBRE_AGRUPACION VOTOS
<fct> <chr> <dbl>
1 Buenos Aires FRENTE DE TODOS 4661554
2 Buenos Aires JUNTOS POR EL CAMBIO 2749946
3 Buenos Aires CONSENSO FEDERAL 711181
4 Buenos Aires FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD 319253
5 Buenos Aires EN BLANCO 304904
6 Buenos Aires UNITE POR LA LIBERTAD Y LA DIGNIDAD 174887
7 Buenos Aires FRENTE NOS 171376
8 Buenos Aires MOVIMIENTO AL SOCIALISMO 71935
9 Buenos Aires FRENTE PATRIOTA 22581
10 Buenos Aires PARTIDO AUTONOMISTA 8783
# … with 254 more rows
> xprov %<>%
+ group_by(PROV) %>%
+ mutate(PCT=round(VOTOS / sum(VOTOS) * 100,2)) %>%
+ ungroup()
> xprov
# A tibble: 264 x 4
PROV NOMBRE_AGRUPACION VOTOS PCT
<fct> <chr> <dbl> <dbl>
1 Buenos Aires FRENTE DE TODOS 4661554 50.7
2 Buenos Aires JUNTOS POR EL CAMBIO 2749946 29.9
3 Buenos Aires CONSENSO FEDERAL 711181 7.73
4 Buenos Aires FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD 319253 3.47
5 Buenos Aires EN BLANCO 304904 3.31
6 Buenos Aires UNITE POR LA LIBERTAD Y LA DIGNIDAD 174887 1.9
7 Buenos Aires FRENTE NOS 171376 1.86
8 Buenos Aires MOVIMIENTO AL SOCIALISMO 71935 0.78
9 Buenos Aires FRENTE PATRIOTA 22581 0.25
10 Buenos Aires PARTIDO AUTONOMISTA 8783 0.1
# … with 254 more rows
> xprov_wide <- xprov %>%
+ select(-VOTOS) %>%
+ spread(NOMBRE_AGRUPACION, PCT)
> xprov_wide
# A tibble: 24 x 12
PROV `CONSENSO FEDER… `EN BLANCO` `FRENTE DE IZQU… `FRENTE DE TODO…
<fct> <dbl> <dbl> <dbl> <dbl>
1 Buen… 7.73 3.31 3.47 50.7
2 Cata… 6.41 7.4 1.33 57.4
3 Chaco 3.44 6.48 1.33 56.0
4 Chub… 8.19 5.8 3.55 51.0
5 Ciud… 8.73 3.23 3.92 33.0
6 Córd… 7.92 3.85 2.68 30.4
7 Corr… 4.93 1.26 1.12 53.0
8 Entr… 8.58 1.89 1.99 45.1
9 Form… 3.7 0.97 0.8 65.9
10 Jujuy 10.0 3.61 3.25 46.1
# … with 14 more rows, and 7 more variables: `FRENTE NOS` <dbl>, `FRENTE
# PATRIOTA` <dbl>, `JUNTOS POR EL CAMBIO` <dbl>, `MOVIMIENTO AL
# SOCIALISMO` <dbl>, `MOVIMIENTO DE ACCION VECINAL` <dbl>, `PARTIDO
# AUTONOMISTA` <dbl>, `UNITE POR LA LIBERTAD Y LA DIGNIDAD` <dbl>
Primero necesitamos obtener el mapa de Argentina con las divisiones políticas, para lo que voy a usar la Database of Global Administrative Areas (GADM):
argentina <- getData("GADM", country="Argentina", level=1)
El siguiente paso es unir la información de la elección con la geográfica:
argentina@data <- left_join(argentina@data, xprov_wide, by=c("NAME_1" = "PROV"))
Ahora podemos crear nuestro mapa. En este código de ejemplo muestro como hacer el mapa para el Frente de Todos pero lo mismo se puede aplicar para el resto simplemente cambiando donde dice FRENTE DE TODOS por el nombre el partido deseado. Para esta parte del código me inspiré cof cof en este post.
contenido_popup <- paste0("<strong>Provincia: </strong>",
argentina$NAME_1,
"<br><strong>Votos: </strong>",
argentina$`FRENTE DE TODOS`,
" <strong>%</strong>")
pal <- colorQuantile(palette = "Blues", domain = NULL, n = 5)
leaflet(data = argentina) %>%
addProviderTiles("CartoDB.Positron") %>%
addPolygons(fillColor = ~pal(`FRENTE DE TODOS`),
fillOpacity = 0.8,
color = "#BDBDC3",
weight = 1,
popup = contenido_popup)
El resultado final es un mapa interactivo que se puede hacer zoom y al hacer click sobre una provincia muestra el porcentaje de voto. Esta es una captura de los resultados de cuatro partidos en esta elección:
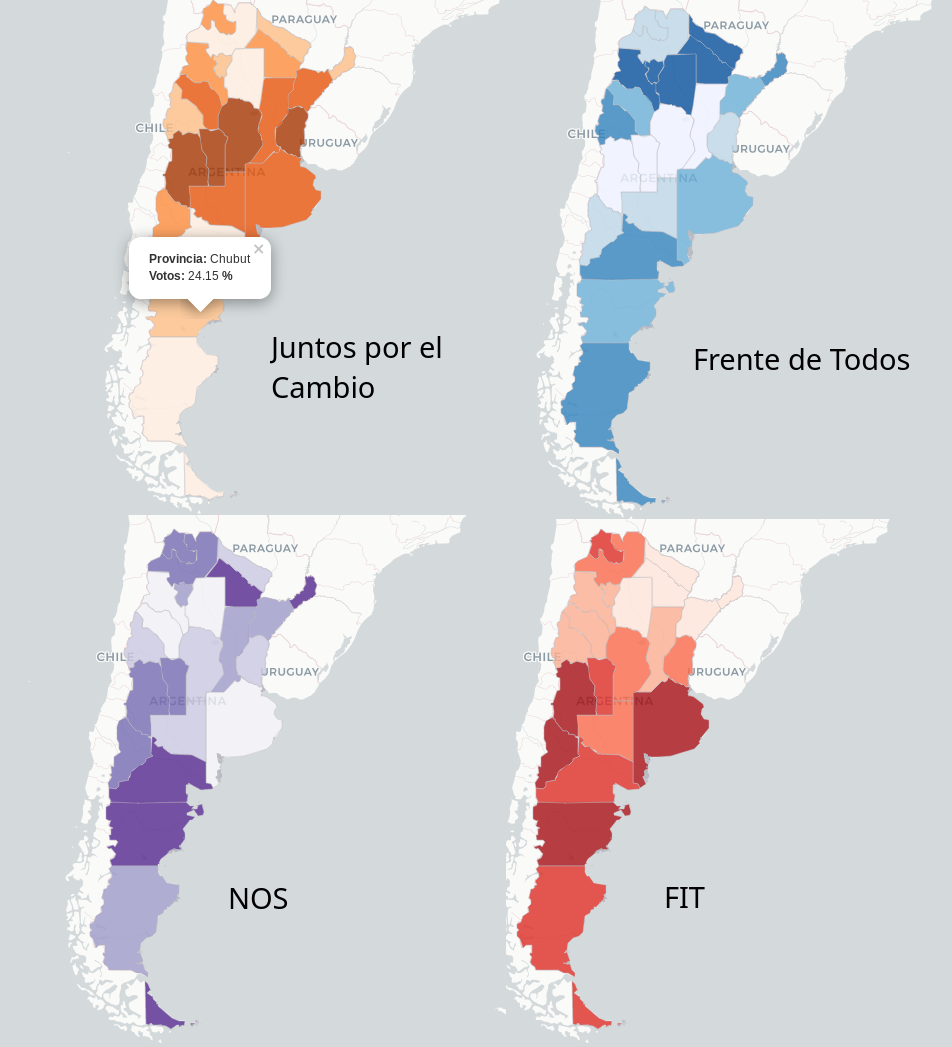
Así terminamos este post sobre las PASO. Nos vemos la próxima y si les gustó el post recuerden comentar / compartir / megustear. Si ven algún error en el post o tienen alguna sugerencia haganmelo saber.
Desde aquí pueden descargar el script completo para R.
Leave a comment